
У серпні 1955 року група вчених подала запит на фінансування в розмірі $13 500 для проведення літнього семінару в Дартмутському коледжі, штат Нью-Гемпшир. Сферою, яку вони пропонували дослідити, був штучний інтелект (ШІ). Хоча запит на фінансування був скромним, гіпотеза дослідників не була такою: «Кожен аспект навчання або будь-яка інша особливість інтелекту може бути, в принципі, настільки точно описана, що може бути створена машина, яка імітуватиме його».
З часу цих скромних починань фільми і засоби масової інформації романтизували ШІ або зображували його як лиходія. Проте для більшості людей ШІ залишився лише предметом дискусій, а не частиною свідомого життєвого досвіду.
Наприкінці минулого місяця ШІ у вигляді ChatGPT вирвався з науково-фантастичних спекуляцій і дослідницьких лабораторій на робочі столи і телефони широкої громадськості. Це так званий «генеративний ШІ» – несподівано розумно сформульована підказка може написати есе або скласти рецепт і список покупок, або створити вірш у стилі Елвіса Преслі.
Хоча ChatGPT став найбільш вражаючим учасником за рік успіху генеративного ШІ, подібні системи продемонстрували ще більший потенціал для створення нового контенту, а підказки, що перетворюють текст на зображення, використовуються для створення яскравих зображень, які навіть перемагали на мистецьких конкурсах. Можливо, ШІ ще не має живої свідомості або теорії розуму, популярної в науково-фантастичних фільмах і романах, але він наближається до того, щоб принаймні зруйнувати те, що, на нашу думку, можуть робити системи штучного інтелекту.
Дослідники, які тісно співпрацюють з цими системами, втратили свідомість від перспективи появи розуму, як у випадку з великою мовною моделлю (LLM) LaMDA від Google. LLM – це модель, яка була навчена обробляти і генерувати природну мову.
Генеративний ШІ також породив занепокоєння щодо плагіату, експлуатації оригінального контенту, який використовується для створення моделей, етики маніпулювання інформацією та зловживання довірою і навіть «кінця програмування».
У центрі всього цього – питання, актуальність якого зростає з часів літнього семінару в Дартмуті: Чи відрізняється ШІ від людського інтелекту? Для того, щоб вважатися ШІ, система повинна демонструвати певний рівень навчання і адаптації. З цієї причини системи прийняття рішень, автоматизації та статистики не є ШІ. ШІ в широкому розумінні поділяється на дві категорії: штучний вузький інтелект (ШІ) та штучний загальний інтелект (ШЗІ). На сьогодні ШЗІ не існує. Ключовим викликом для створення загального ШІ є адекватне моделювання світу з усією сукупністю знань, у послідовний і корисний спосіб. Це, м’яко кажучи, масштабне завдання.
Більшість з того, що ми знаємо як ШІ сьогодні, має вузький інтелект – коли конкретна система розв’язує конкретну проблему. На відміну від людського інтелекту, такий вузький інтелект ШІ ефективний лише в тій сфері, в якій він був навчений: наприклад, виявлення шахрайства, розпізнавання облич або соціальні рекомендації. А ШІ функціонуватиме так само як і людина. Наразі найпомітнішим прикладом спроб досягти цього є використання нейронних мереж і глибокого навчання, навчених на величезних обсягах даних.
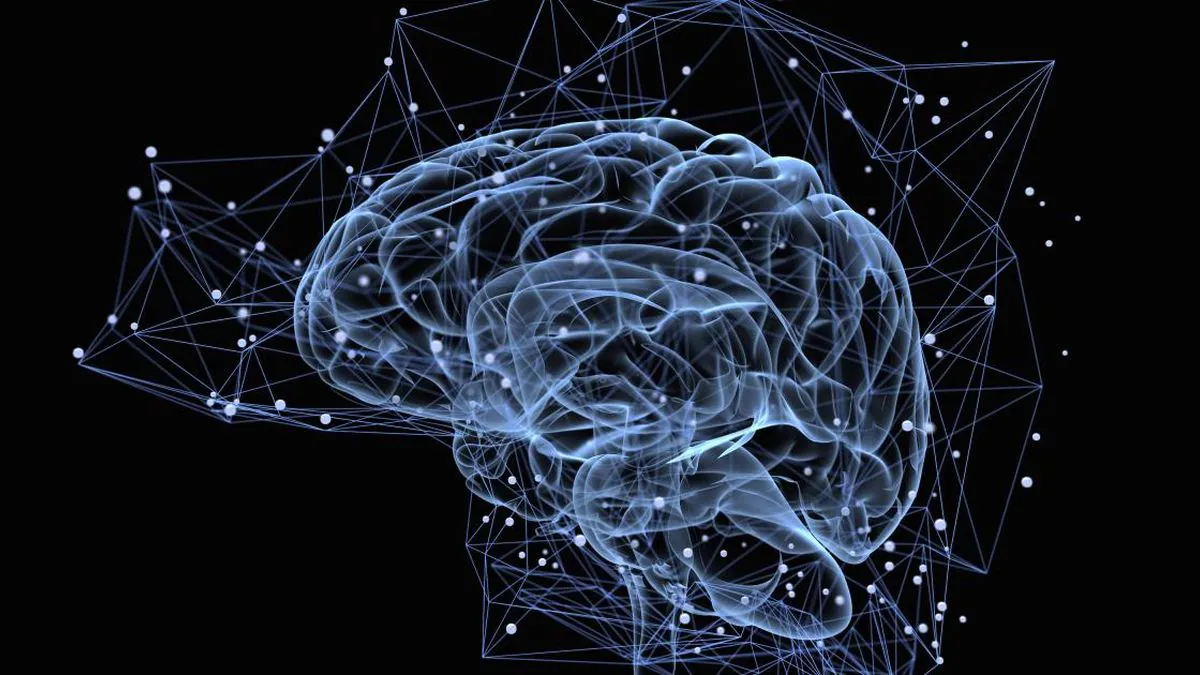
Нейронні мережі натхненні тим, як працює людський мозок. На відміну від більшості моделей машинного навчання, які виконують обчислення на навчальних даних, нейронні мережі працюють, подаючи кожну точку даних по черзі через взаємопов’язану мережу, щоразу коригуючи параметри. У міру того, як через мережу пропускається все більше і більше даних, параметри стабілізуються, кінцевим результатом є «навчена» нейронна мережа, яка потім може видавати бажаний результат на нових даних – наприклад, розпізнавати, чи містить зображення кішку або собаку.
Значний стрибок у розвитку штучного інтелекту сьогодні зумовлений технологічними удосконаленнями способів навчання великих нейронних мереж, що дозволяють коригувати величезну кількість параметрів під час кожного прогону завдяки можливостям великих інфраструктур хмарних обчислень. Наприклад, GPT-3 (система штучного інтелекту, на якій працює ChatGPT) – це велика нейронна мережа зі 175 мільярдами параметрів.
Для успішної роботи штучному інтелекту потрібні три речі. По-перше, йому потрібні якісні, об’єктивні дані, причому багато. Дослідники, які будують нейронні мережі, використовують великі масиви даних, які з’явилися завдяки оцифруванню суспільства.
Co-Pilot, що доповнює людей-програмістів, черпає свої дані з мільярдів рядків коду, розміщених на GitHub. ChatGPT та інші великі мовні моделі використовують мільярди веб-сайтів і текстових документів, що зберігаються в Інтернеті.
Інструменти перетворення тексту на зображення, такі як Stable Diffusion, DALLE-2 і Midjourney, використовують пари зображення-текст з таких наборів даних, як LAION-5B. Моделі ШІ і надалі розвиватимуться в міру того, як ми оцифровуватимемо все більше нашого життя і надаватимемо їм альтернативні джерела даних, такі як імітаційні дані або дані з ігрових налаштувань, таких як Minecraft.
ШІ також потребує обчислювальної інфраструктури для ефективного навчання. Оскільки комп’ютери стають потужнішими, моделі, які зараз вимагають інтенсивних зусиль і масштабних обчислень, в недалекому майбутньому можуть оброблятися локально. Наприклад, модель Stable Diffusion вже можна запускати на локальних комп’ютерах, а не в хмарних середовищах. Третя потреба в ШІ – це вдосконалені моделі і алгоритми. Системи, керовані даними, продовжують стрімко прогресувати в областях, які колись вважалися територією людського пізнання.
Проте, оскільки світ навколо нас постійно змінюється, системи ШІ потребують постійного перенавчання з використанням нових даних. Без цього важливого кроку системи штучного інтелекту даватимуть відповіді, які фактично не відповідають дійсності або не враховують нову інформацію, що з’явилася з моменту їх навчання.
Нейронні мережі – не єдиний підхід до ШІ. Іншим помітним табором у дослідженнях штучного інтелекту є символічний ШІ – замість того, щоб перетравлювати величезні масиви даних, він спирається на правила і знання, подібні до людського процесу формування внутрішніх символічних уявлень про ті чи інші явища.
Але за останнє десятиліття баланс сил сильно схилився в бік підходів, заснованих на даних, а «батьки-засновники» сучасного глибокого навчання нещодавно були нагороджені Премією Тьюринга, еквівалентом Нобелівської премії в галузі інформатики.
Дані, обчислення і алгоритми складають основу майбутнього ШІ. Усі показники вказують на те, що в осяжному майбутньому буде досягнутий швидкий прогрес в усіх трьох категоріях.
Ви можете допомогти Україні боротися з російськими окупантами. Найкращий спосіб зробити це – пожертвувати кошти Збройним Силам України через Savelife або через офіційну сторінку НБУ.




Leave a Reply